
Инструменты для оптимизации конверсий в контекстной рекламе – крайне популярны среди рекламодателей в последнее время. Базовой целью подобных сервисов является расчет ставок для ключевиков, что позволили бы прийти к желаемым ключевым показателям, которые установили как цель оптимизации. Классический пример подобной задачи – оптимизация по CPA (Cost Per Action). В такой ситуации целью оптимизатора будет получение максимального числа конверсий (целевых действий), средняя цена которых была бы не больше определенного целевого ограничения CPA. Также можно говорить и о иных стратегиях оптимизации.
На современном технологическом рынке есть много систем, которые могут управлять ставками. Но особо эффекта от оптимизации они не приносят. По крайней мере, клиентам со средним бюджетом. Это происходит по ряду причин. Так, все оптимизаторы опираются на собранные за некоторый период данные. Чем больше бюджет аккаунта, тем больше статистики, которая нужна при расчете оптимальных ставок. Помимо этого, объем бюджета оказывает влияние на скорость сбора данных, и на скорость, с которой работают оптимизаторы. Подтверждение – в справке Директа по автоматической стратегии управления ставками в кампании:
Целевые визиты за 28 дней + 0,01 × клики за 28 дней ≥ 40
— это является порогом оптимизации для автоматической стратегии по CPA (для единой кампании)
Стратегия хорошо работает для кампаний с объемом кликов в неделю более 200 и числом целевых визитов более 10 за 7 дней.
— а это считается критерием, что дает гарантию эффективности оптимизации.
Немногие из рекламных кампаний подходят под данный «фильтр». Рассмотрим эту проблему подробнее.
Все мы знаем о принципе Парето: «20 % усилий приносят 80 % результата».
В контекстной рекламе он также работает, но немного в другой пропорции: «На 5 % ключевиков приходится 95 % трафика».
Так как оптимизаторы конверсий принимают решение об оптимальной ставке по каждой из ключевых фраз отдельно, то логичное решение может быть принято лишь для 5 % фраз. Все ключевые фразы можно разделить на 3 группы по объему статистики (за опорный период):
.png)
Перед тем, как обсуждать разные подходы по вычислению ставок при недостаточном количестве данных, важно понять, как именно эти данные конвертируются в оптимальную ставку. Данное преобразование делится на 2 блока:
Расчет прогнозируемого коэффициента (CR) конверсии ключевика; Расчет оптимальной ставки по вычисленному CR и установленных KPI.
Поговорим о втором блоке. Допустим, мы сделали прогноз коэффициента конверсии CR по фразе. Если клиент установил целевые KPI и по фразе накопилась некоторая статистика ST по нужным ключевым метрикам, то оптимальная ставка Bid будет рассчитана как определенная функция от параметров, о которых мы говорили ранее. Определенный вид данной функции зависит и от метрик, и от стратегии оптимизации вместе с KPI. К примеру, для стратегии оптимизации по CPA простой формулой для расчета ставки будет такая:
![]()
В случае с другими стратегиями нужно работать с более сложными формулами.
Центральным моментом в расчете ставки будет точный прогноз коэффициента конверсии, что делается до момента вычисления ставки. Коэффициент конверсии ключевика считается вероятностью того, что клик по фразе поспособствует конверсии. С достаточным объемом кликов CL и конверсий CV, данный коэффициент может считаться так:
![]()
Но работа с этой формулой «в лоб» с малым объемом статистики приведет к неточному прогнозированию коэффициента.
«Простую» формулу расчета CR применима лишь для ключевиков, у которых статистики – достаточно. Таких фраз будет 5 %. А 95 % фраз остаются без внимания.
Для исправления ситуации необходимо использовать разные методики. Вот некоторые из них:
Крайний метод особенно хорошо работает в системах оптимизации контекстной рекламы. Поговорим о нем подробнее.
Пулинг – это «умный» прирост статистики по ключевику по причине займа статистики по другим фразам. Для понимания принципа классического пулинга, нужно рассмотреть строение рекламного аккаунта:
.png)
Он имеет древовидную структуру. «Корень» - это аккаунт, а в роли «листьев» выступают ключевые фразы.
Ключевики находятся в связи с объявлениями, показ которых они инициируют. Объявления объединяются в группы, которые в свою очередь становятся рекламной кампанией. Если требуется сделать прогноз CR по ключевику, своей статистики по которому не хватает, то мы объединяем статистику по группе объявлений, которой принадлежит данная фраза. Или же по кампании. И так до того момента, пока статистики не будет достаточно для принятия решения о значении прогноза CR. Графически это можно изобразить так:
.png)
Простая формула пулинга выглядит так:
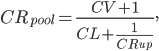
Модель делает прогноз того, какое число кликов нужно фразе для получения еще одной конверсии.
CRup можно рассчитывать напрямую, но только если на текущем уровне достаточно статистики.
Пример. Допустим, по фразе X случилось 5 кликов и 1 конверсия. А по группе объявлений, где находится X, накопилось 100 кликов и 5 конверсий. Предположим, что 100 кликов хватит для принятия решения насчет оптимальной ставки. В итоге получается:
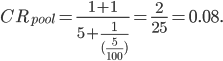
Метод пулинга, а также ряд его обобщений, можно использовать в системах автоматизации контекстной рекламы. Так, наиболее известная в мире по управлению рекламой в Сети Marin Software сделала патент своей модели (патент US PTO 60948670):
![]()
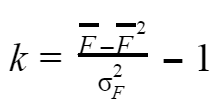
Так, чем чем больше значение дисперсии, тем меньше будет k. И, соответственно, меньше влияния будет иметь следующий уровень в прогнозе коэффициента. Значение ![]() покажет, как близки друг к другу коэффициенты.
покажет, как близки друг к другу коэффициенты.
С классической моделью ![]() будет находиться в зависимости от качества работы с рекламным аккаунтом.
будет находиться в зависимости от качества работы с рекламным аккаунтом.
Также стоит отметить, что иерархический пулинг делает учет исключительно статистики по фразам, обходя ее структуру.
По этой причине стоит рассмотреть иной подход к прогнозу коэффициента.
Основной идеей является отказ от иерархического строения во время пулинга. Взамен этому нужно делать анализ текстового сходства ключевиков и собирать «ядро» фразы. Мы получаем набор ключевых фраз, что очень близки по содержанию к той, что мы подвергли анализу. Этот процесс – довольно итеративный: во время добавления новой фразы в набор, необходимо делать анализ его состава и оценивать, хватит ли статистики для принятия решения о ставке. После сбора в кластере нужного объема данных, процесс переходит в режим «стоп».
Это можно описать как нечто такое:

А это – кластеры в более детальном рассмотрении:
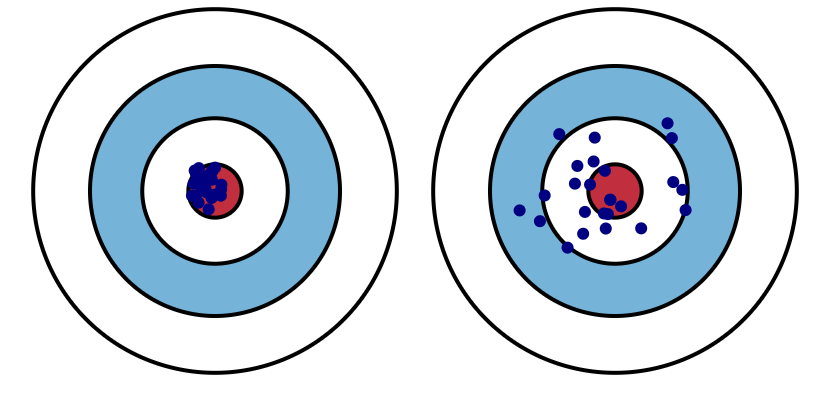
Слева – ключевики с небольшой дисперсией коэффициента конверсии, а справа – с большой. Если дисперсия большая, то нужно будет добавлять больше фраз, а сам прогноз будет не слишком точным из-за рассеянности от центра. По этой причине нужно заблаговременно выбрать метрику схожести слов, которая свела бы дисперсию к минимуму.
Кластеризация на базе текстовой схожести делает меньше дисперсию внутри кластера по коэффициенту конверсии. Это увеличивает точность прогноза конверсии по ключевику и поможет рассчитать ставки более корректно. С ним можно работать для оптимизации тех слов, своей статистики по которым не хватает для принятия решения насчет оптимальной ставки.