
SEOnews запустил проект для специалистов и клиентов «Энциклопедия интернет-маркетинга», в рамках которого редакция публикует обучающие материалы от ведущих агентств на рынке. В итоге мы планируем выпустить полное, практически полезное и актуальное электронное руководство.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенная директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индексапоисковых систем, а значит, потеряет весь поисковый трафик.
Если вы уже знакомы с основами составления robots.txt, можете сразу переходить к пункту 3 «Составление robots.txt»
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем...
Сессия (робота поисковой системы) начинается с загрузки файла robots.txt. Если файл отсутствует, не является текстовым или на запрос робота возвращается HTTP-статус отличный от 200 OK, робот считает, что доступ к документам (страницам сайта) не ограничен.
То есть, другими словами, robots.txt – набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
|
<Директива><двоеточие><пробел><документ, к которому применяется директива> |
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent – указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
Disallow – директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
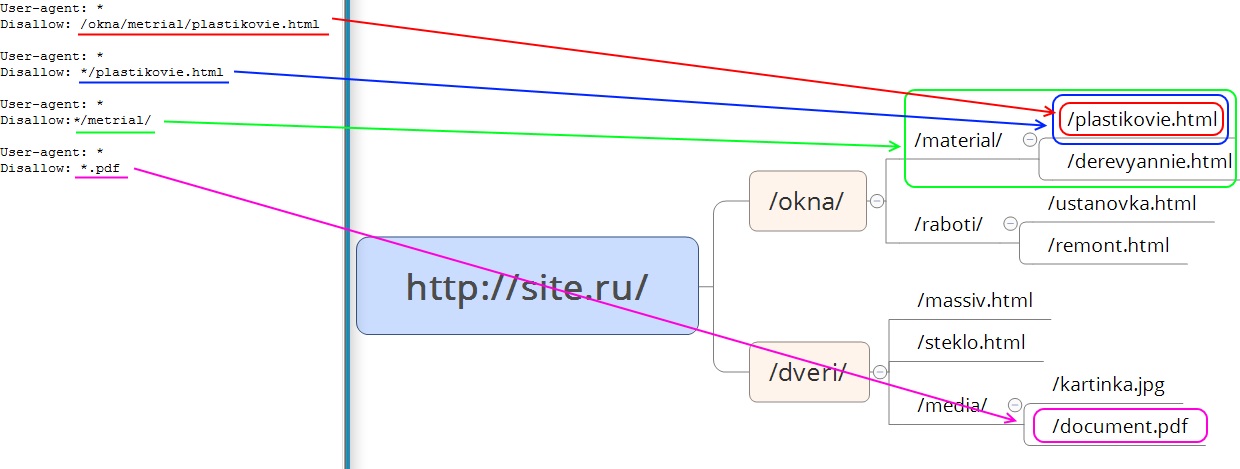
Рис. 1 Директива Disallow
Allow – директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
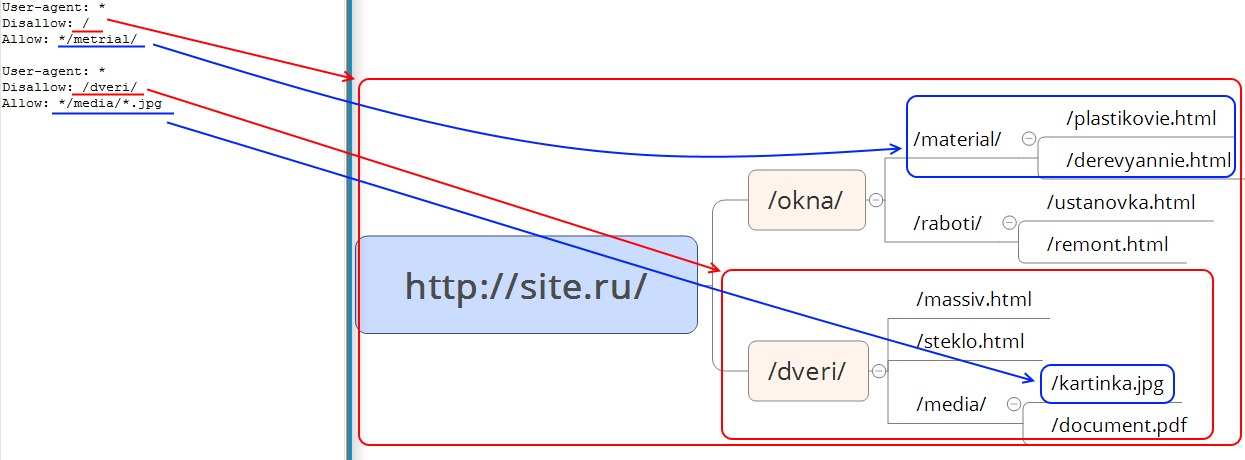
Рис. 2 Директива Allow
Sitemap – директива для указания пути к файлу xml-карты сайта.
|
User-agent: * Sitemap: http://site.ru/sitemap-1.xml Sitemap: http://site.ru/sitemap-2.xml |
Спецсимволы
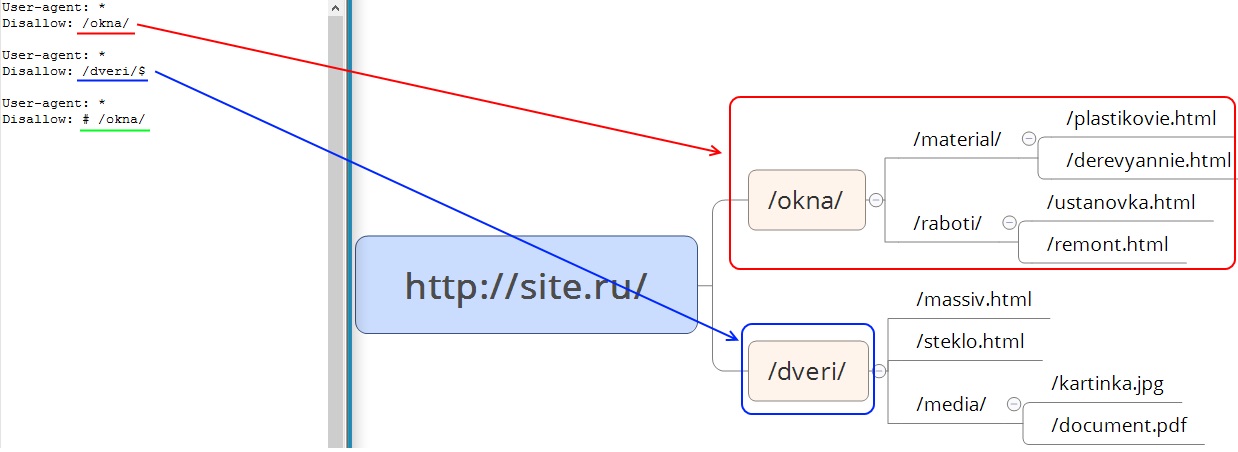
Рис. 3 Спецсимволы
Host – директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay – директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
Clean-param – директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
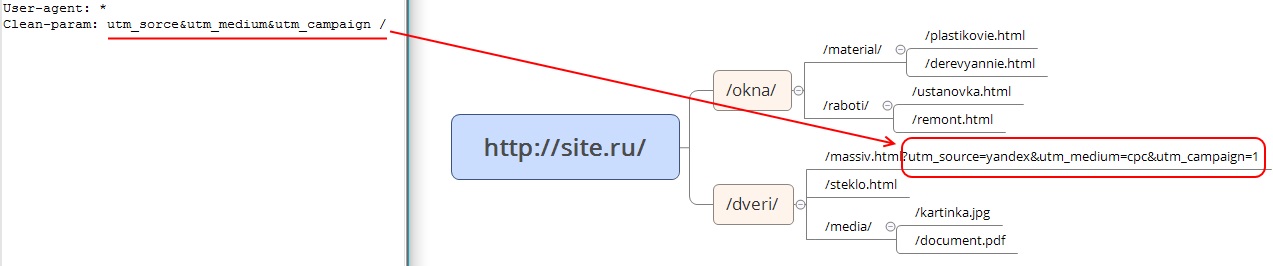
Рис. 4 Clean-param
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
Чтобы указать главное зеркало в Google необходимо подтвердить оба зеркала (www.site.ru и site.ru) в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта» и в блоке «Основной домен» выбрать главное зеркало и сохранить изменения.
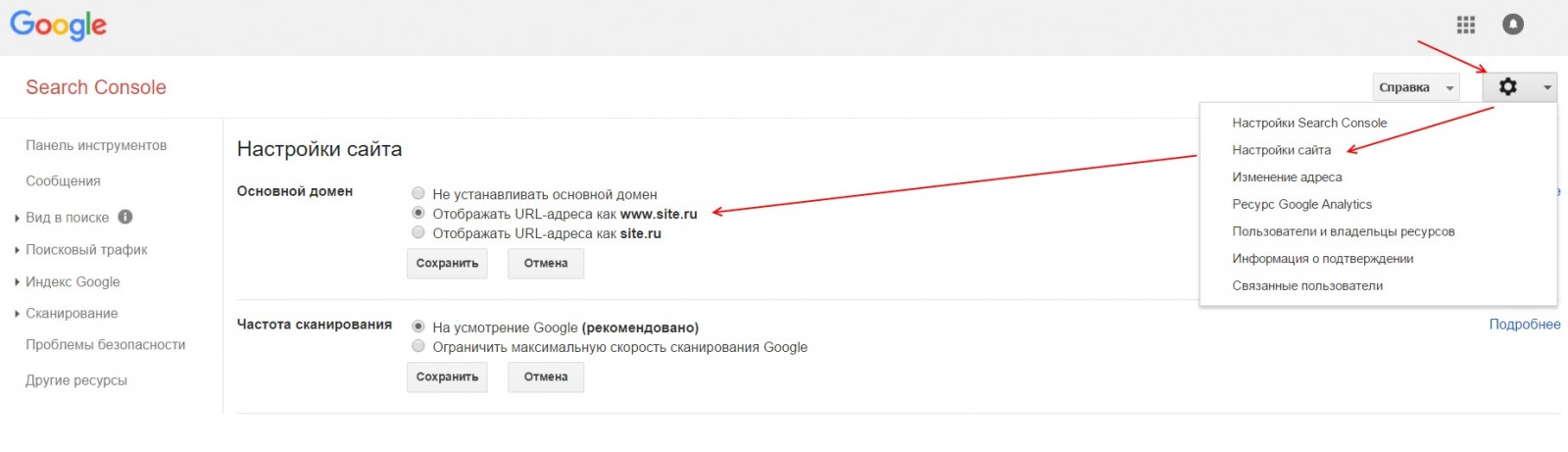
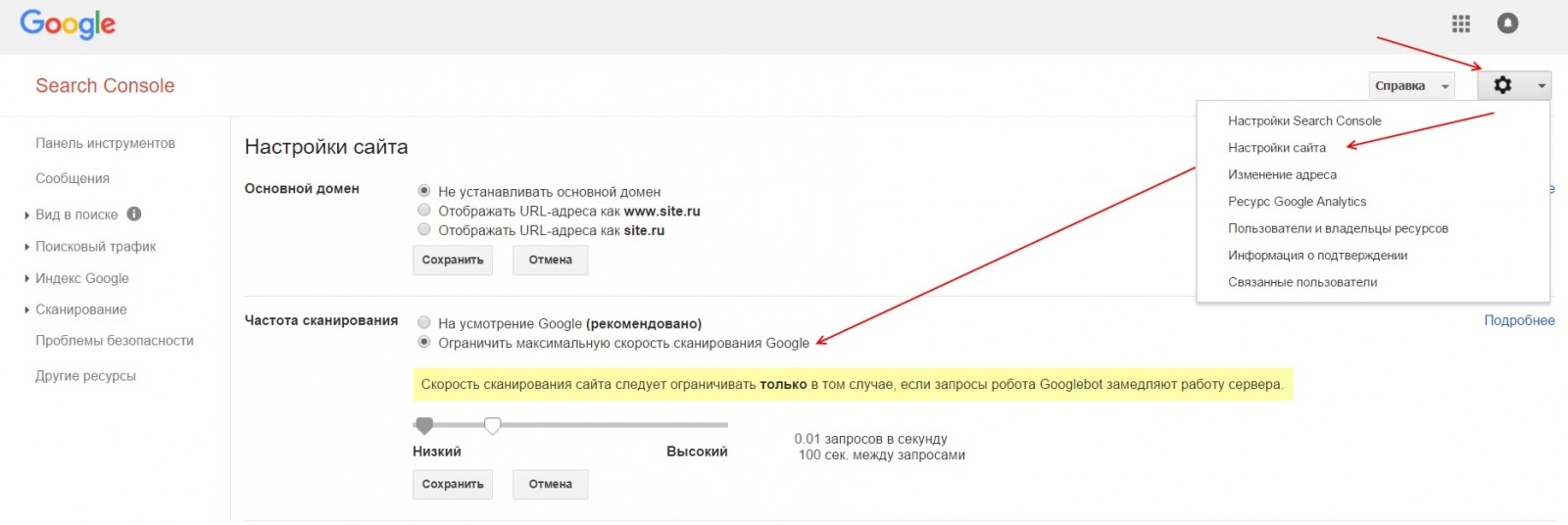
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» – «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
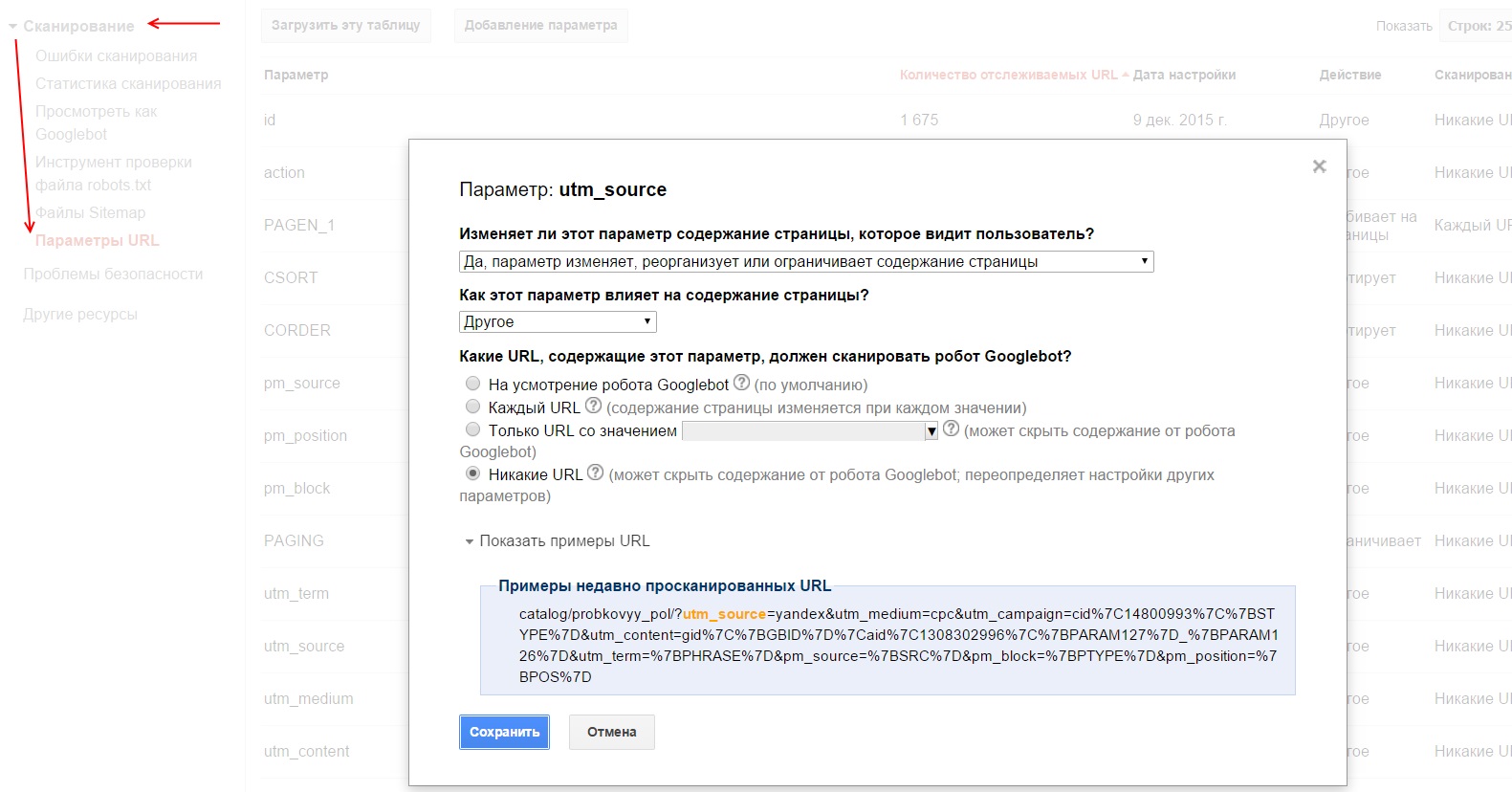
Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
|
User-agent: Yandex # Наиболее часто встречаемые расширения документов Disallow: /*.pdf Disallow: /*.xls Disallow: /*.doc Disallow: /*.ppt Disallow: /*.txt # Требуется для правильно обработки ПС Allow: /*/<папка содержащая css>/*.css Allow: /*/<папка содержащая js>/*.js # Картинки Allow: /*/<папка содержащая медиа файлы>/*.jpg Allow: /*/<папка содержащая медиа файлы>/*.jpeg Allow: /*/<папка содержащая медиа файлы>/*.png Allow: /*/<папка содержащая медиа файлы>/*.gif # Наиболее часто встречаемые метки для отслеживания рекламы Clean-param: utm_source&utm_medium&utm_term&utm_content&utm_campaign&yclid&gclid&_openstat&from / # При наличии фильтров и параметров добавляем и их в Clean-param Host: site.ru
User-agent: Googlebot Disallow: /*.pdf Disallow: /*.xls Disallow: /*.doc Disallow: /*.ppt Disallow: /*.txt Allow: /*/<папка содержащая css>/*.css Allow: /*/<папка содержащая js>/*.js Allow: /*/<папка содержащая медиа файлы>/*.jpg Allow: /*/<папка содержащая медиа файлы>/*.jpeg Allow: /*/<папка содержащая медиа файлы>/*.png Allow: /*/<папка содержащая медиа файлы>/*.gif # У google метки, фильтры и параметры закрываются в GSC-Сканирование-Параметры URL
User-agent: * # Метки, фильтры и параметры для других ПС закрываем по классическому стандарту Disallow: /*utm Disallow: /*clid= Disallow: /*openstat Disallow: /*from Disallow: /*.pdf Disallow: /*.xls Disallow: /*.doc Disallow: /*.ppt Disallow: /*.txt Allow: /*/<папка содержащая css>/*.css Allow: /*/<папка содержащая js>/*.js Allow: /*/<папка содержащая медиа файлы>/*.jpg Allow: /*/<папка содержащая медиа файлы>/*.jpeg Allow: /*/<папка содержащая медиа файлы>/*.png Allow: /*/<папка содержащая медиа файлы>/*.gif Sitemap: http://site.ru/sitemap.xml |
* Напомним, что в указанном шаблоне присутствует спецсимвол комментария «#», и все что находится справа от него предназначается не для роботов, а является подсказками для людей.
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
|
User-agent: * Disallow: / |
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
|
User-agent: * Host: site.ru # В то время, как правильное зеркало sub.site.ru |
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
Кроме файла robots.txt существует множество других способов управления индексацией сайта. Но по нашему опыту, правильный robots.txt помогает продвинуть сайт и защитить его от многих серьезных ошибок.
Надеемся, наш опыт, изложенный в данной статье, поможет вам разобраться с основными принципами составления robots.txt.